Autonomous Security Operations - AI Driven Automation for Resilient SecOps
Unleash your SOC's True Potential: From Toil to Strategic Oversight
Free your security experts from the noise of repetitive alerts. Netenrich Autonomous Security Operations applies Agentic AI that acts on your behalf, autonomously handling known threats and repetitive tasks. This AI Core ruthlessly automates the known and adapts playbooks in real time, while your analysts shift from alert-chasing to strategic oversight.
.png?width=900&height=900&name=Autonomous%20SOC%20(1).png)




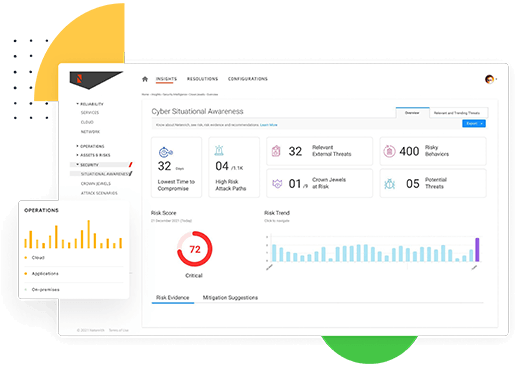
Your Security Operations are at a Tipping Point
Even the best SOC models degrade within 3-4 years, buried in toil, tool fatigue, and alert noise. Old playbooks are reactive and static, while attackers move in minutes, not days.![]()
.png?width=30&height=30&name=tick%20(2).png) Limited Visibility from Fragmented Tools
Limited Visibility from Fragmented Tools
Fragmented tools and manual processes block real-time insights across cloud, on-prem, and remote endpoints thereby leaving blind spots.-
Alert Overload and Constant Firefighting
Analysts drown in endless alerts and reactive workflows, chasing noise instead of anticipating the next threat. -
Growing Talent Drain
Skilled experts burn out, reduced to tool operators instead of true threat hunters.
Free Up Intellect. Focus on What Matters.
Netenrich Autonomous Security Operations replaces reactive models with proactive, automation-first SecOps. By embedding Agentic AI into detection, triage, and response, CISOs achieve resilience without scaling headcount.

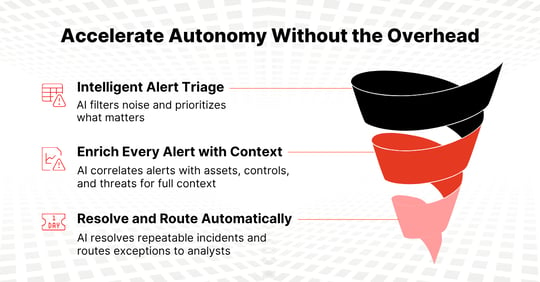
Automate the Known with an AI Core
We build an AI Core that ruthlessly automates repetitive triage, enrichment, and ticket handling. This eliminates noise and accelerates response time.

Shift from Reactive to Proactive Investigations
With noise eliminated, analysts transform into AI Supervisors and proactive threat hunters. Instead of chasing tickets, they run hypothesis-driven investigations, validate anomalies, and assess business risk across APIs, containers, identities, and AI-driven services.
![]()
.png?width=25&height=25&name=tick%20(2).png) Always-On Defense
Always-On Defense
Noise-Free Operations
Faster Incident Response
Resilient SecOps at Scale

52%+ lower operating costs
Faster MTTD/MTTR with automated workflows

Integrated MDR services for ongoing resilience

Proactive visibility into known and unknown threats
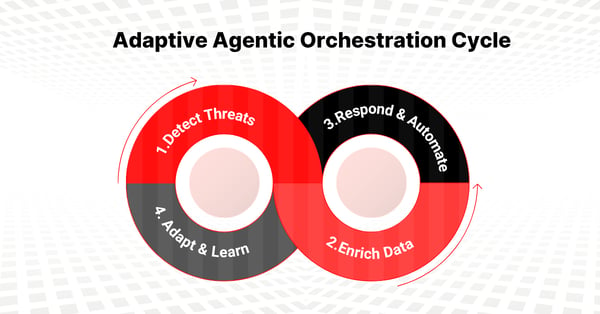
Adaptive Agentic Orchestration
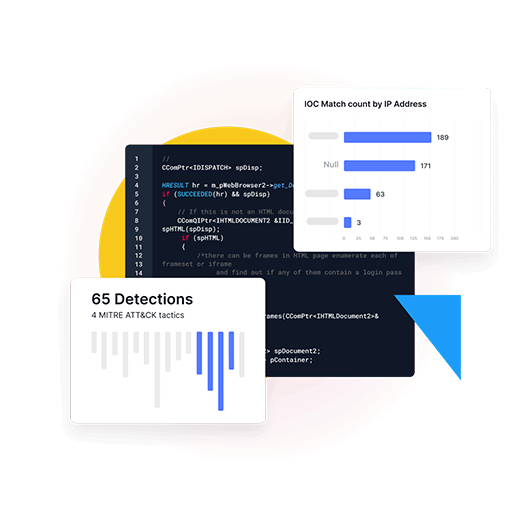
Our specialized AI agents orchestrate detection, enrichment, and response across your stack, transforming static SOAR playbooks into adaptive, context-aware automation.![]()

From Alert Operators to AI Supervisors.
Analysts aren’t replaced, they’re elevated. As AI Supervisors, they focus on ensuring the system works as expected: validating AI outputs, spotting gaps, and strengthening detections. Instead of just reviewing alerts, they guide efficacy and outcomes.
Accelerate Autonomy Without the Overhead
Building and maintaining an autonomous SOC on your own takes years of engineering and scarce AI/ML expertise. With Netenrich, you get the outcomes without the burden. We embed our experts, co-source capabilities, and continuously evolve your SOC into a semi-autonomous model that delivers results fast.