



.png)
20 min read
LiteLLM PyPI Supply Chain Attack: What Happened & How to Fix It
Overview
On March 24, 2026, two malicious versions of the litellm Python...


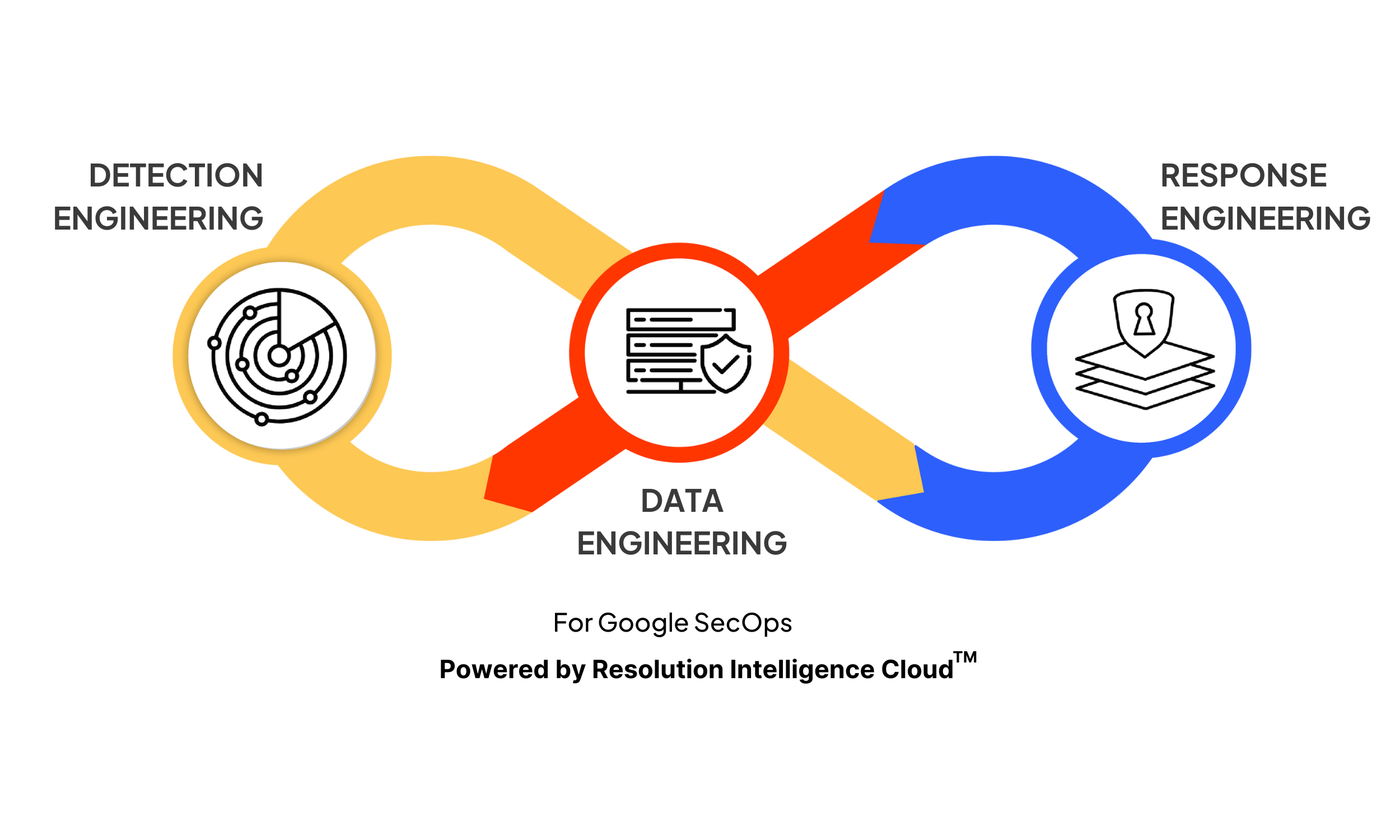
Powered by our Resolution Intelligence Cloud™ technology, Netenrich Adaptive MDR for Google Chronicle SecOps moves you one step closer to achieving autonomic security operations (ASO).
Our model operates on an agile, continuous loop of data engineering, detection engineering, and response engineering so you get comprehensive protection, tailored to meet the unique and evolving needs of your specific environment and business.
“One of Resolution Intelligence Cloud’s strongest differentiators lies in its intelligent routing and IT ops capabilities, which effectively direct issues to the right parties.”
“What if we can detect that something is not healthy, before it crashes? In partnership with Netenrich we are excited to… automate that work so that we can actually send the technician to go fix it before it breaks.”
"Companies are expecting much more from CISOs today. Theirs is a critical field that requires a high level of expertise, thoughtfulness, and intentionality.... By partnering with companies like Netenrich, CISOs and SOCs can gain more expertise to drive predictable outcomes for customers."


Read the Predict 2025: There Will Never Be an Autonomous SOC report by Gartner, to explore how leading organizations strike the right balance between AI and human expertise.